آموزش نصب ELK (Elasticsearch + kibana) بر روی سیستم عامل اوبونتو ۲۲.۰۴

استک ELK مجموعهای از سه ابزار متنباز است که برای جمعآوری، پردازش و تجسم دادههای غیرساختاریافته استفاده میشود. این سه ابزار عبارتند از:
ابزار Elasticsearch: یک موتور جستجو و تحلیل متن باز و توزیعپذیر است که بر روی کتابخانه Apache Lucene ساخته شده است.
ابزار Logstash: یک ابزار جمعآوری و پردازش دادههای متن باز است که میتواند دادهها را از منابع مختلف جمعآوری کرده و آنها را برای پردازش بیشتر در Elasticsearch آماده کند.
ابزار Kibana: یک ابزار تجسم دادههای متن باز است که میتواند دادههای ذخیرهشده در Elasticsearch را به صورت بصری نمایش دهد.
به مجموعه این سه ابزار در اصطلاح ELK گفته میشود. استک ELK میتواند برای طیف گستردهای از کاربردها استفاده شود، از جمله:
- مانیتورینگ و عیبیابی سیستمهای IT
- تجزیه و تحلیل دادههای مشتری
- هوش عملیاتی (BI)
- هوش مصنوعی و یادگیری ماشینی
استک ELK یک راهحل قدرتمند و انعطافپذیر برای جمعآوری، پردازش و تجسم دادههای غیرساختاریافته است.
نحوه نصب Elasticsearch، Logstash و Kibana در اوبونتو ۲۲.۰۴
Elastic Stack – که قبلا به عنوان ELK Stack شناخته میشد، مجموعهای از نرمافزار منبع باز تولید شده توسط Elastic است که به شما امکان جستجو، تجزیه و تحلیل و تجسم گزارشهای تولید شده از هر منبعی را در هر قالبی میدهد، عملی که به عنوان ثبت متمرکز شناخته میشود. ثبت متمرکز میتواند هنگام تلاش برای شناسایی مشکلات سرورها یا برنامههای شما مفید باشد، زیرا به شما امکان میدهد همه گزارشهای خود را در یک مکان جستجو کنید. همچنین مفید است زیرا به شما این امکان را میدهد تا مسائلی را که چندین سرور را در بر میگیرند با مرتبط کردن گزارشهای آنها در یک بازه زمانی خاص شناسایی کنید.
استک الاستیک چهار جزء اصلی دارد:
- Elasticsearch: یک موتور جستجوی RESTful توزیع شده که تمام داده های جمع آوری شده را ذخیره می کند.
- Logstash: جزء پردازش داده های Elastic Stack که داده های دریافتی را به Elasticsearch ارسال می کند.
- Kibana: یک رابط وب برای جستجو و تجسم گزارشها.
- Beats: فرستنده داده های سبک وزن و تک منظوره که می توانند داده ها را از صدها یا هزاران دستگاه به Logstash یا Elasticsearch ارسال کنند.
در این آموزش، Elastic Stack را روی سرور اوبونتو ۲۲.۰۴ نصب خواهید کرد. شما یاد خواهید گرفت که چگونه تمام اجزای Elastic Stack را نصب کنید – از جمله Filebeat، بیتی که برای ارسال و متمرکز کردن گزارشها و فایلها استفاده میشود – و آنها را برای جمعآوری و تجسم گزارشهای سیستم پیکربندی کنید. علاوه بر این، از آنجایی که کیبانا معمولاً فقط در لوکال هاست در دسترس است، ما از Nginx برای پروکسی آن استفاده می کنیم تا از طریق یک مرورگر وب قابل دسترسی باشد. ما تمام این اجزا را روی یک سرور نصب می کنیم که از آن به عنوان سرور Elastic Stack خود یاد می کنیم.
مرحله ۱: نصب و پیکربندی Elasticsearch
اجزای Elasticsearch در مخازن بسته پیش فرض اوبونتو در دسترس نیستند. با این حال، پس از افزودن لیست منبع بسته Elastic، می توان آنها را با APT نصب کرد.
همه بسته ها با کلید امضای Elasticsearch امضا می شوند تا از سیستم شما در برابر جعل بسته محافظت شود. بسته هایی که با استفاده از کلید احراز هویت شده اند، قابل اعتماد تلقی می شوند. در این مرحله، کلید عمومی GPG Elasticsearch را وارد کرده و لیست منبع بسته Elastic را برای نصب Elasticsearch اضافه میکنید.
برای شروع، از cURL، ابزار خط فرمان برای انتقال داده ها با URL ها، برای وارد کردن کلید GPG عمومی Elasticsearch به APT استفاده کنید. توجه داشته باشید که ما از آرگومانهای -fsSL استفاده میکنیم تا همه پیشرفتها و خطاهای احتمالی را خاموش کنیم (بهجز خرابی سرور) و به cURL اجازه میدهیم در صورت تغییر مسیر، در یک مکان جدید درخواست ارسال کند. خروجی دستور curl را به دستور gpg –dearmor وارد کنید، که کلید را به قالبی تبدیل می کند که apt می تواند از آن برای تأیید بسته های دانلود شده استفاده کند.
#curl -fsSL https://artifacts.elastic.co/GPG-KEY-elasticsearch |sudo gpg –dearmor -o /usr/share/keyrings/elastic.gpg
این دستور، کلید عمومی Elasticsearch را از سایت artifacts.elastic.co دانلود و در سیستم عامل شما نصب میکند. کلید عمومی Elasticsearch، برای تأیید اصالت فایلهای دانلود شده از این سایت مورد نیاز است.
شرح دستور:
- curl -fsSL https://artifacts.elastic.co/GPG-KEY-elasticsearch: این دستور، فایل کلید عمومی Elasticsearch را از سایت artifacts.elastic.co دانلود میکند.
- |sudo gpg –dearmor -o /usr/share/keyrings/elastic.gpg: این دستور، فایل دانلود شده را با استفاده از ابزار GPG از حالت فشرده خارج میکند و آن را در مسیر /usr/share/keyrings/elastic.gpg نصب میکند.
جزئیات دستور:
- -fsSL: این گزینههای curl، نشان میدهند که باید از پروتکل HTTPS استفاده شود، فایل باید با موفقیت دانلود شود و در صورت وجود هرگونه خطا، خروجی باید به صورت خطی باشد.
- –dearmor: این گزینهی gpg، نشان میدهد که باید فایل فشرده شده را از حالت فشرده خارج کرد.
- -o /usr/share/keyrings/elastic.gpg: این گزینهی gpg، نشان میدهد که باید فایل خروجی در مسیر /usr/share/keyrings/elastic.gpg ذخیره شود.
نتیجه دستور:
با اجرای این دستور، کلید عمومی Elasticsearch در سیستم عامل شما نصب میشود. این کلید، برای تأیید اصالت فایلهای دانلود شده از سایت artifacts.elastic.co مورد نیاز است.
سپس، فهرست منبع Elastic را به فهرست sources.list.d اضافه کنید، جایی که APT منابع جدید را جستجو می کند:
#echo “deb [signed-by=/usr/share/keyrings/elastic.gpg] https://artifacts.elastic.co/packages/7.x/apt stable main” | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
در مرحله بعد، لیست بستههای اوبونتوی خود را به روز کنید تا APT منبع جدید Elastic را بخواند:
#apt update
سپس Elasticsearch را با این دستور نصب کنید:
#apt install elasticsearch
Elasticsearch اکنون نصب شده و آماده پیکربندی است. از ویرایشگر متن دلخواه خود برای ویرایش فایل پیکربندی اصلی یعنی elasticsearch.yml استفاده کنید. ما در اینجا از vim استفاده خواهیم کرد:
#vim /etc/elasticsearch/elasticsearch.yml
توجه: فایل پیکربندی Elasticsearch در قالب YAML است، که یک زبان نشانهگذاری ساده است که برای مشخص کردن دادهها استفاده میشود. در YAML، استفاده از تورفتگی برای نشان دادن ساختار دادهها ضروری است. اگر تورفتگی صحیح را حفظ نکنید، Elasticsearch نمیتواند فایل پیکربندی را به درستی تفسیر کند. برای اطمینان از اینکه فضای اضافی هنگام ویرایش فایل پیکربندی Elasticsearch ایجاد نمیشود، میتوانید از یک ویرایشگر متن که از قالب YAML پشتیبانی میکند استفاده کنید. این ویرایشگرها معمولاً دارای ویژگیهایی هستند که به شما کمک میکنند تا تورفتگی صحیح را حفظ کنید.
فایل elasticsearch.yml گزینه های پیکربندی برای کلاستر، نود، مسیرها، حافظه، شبکه، دیسکاوری و گیتوی شما را فراهم میکند. اکثر این گزینهها در فایل از قبل پیکربندی شدهاند اما شما میتوانید آنها را بر اساس نیاز خود تغییر دهید. برای یک راه اندازی ساده، ما فقط تنظیمات میزبان شبکه را تنظیم میکنیم.
برای محدود کردن دسترسی و در نتیجه افزایش امنیت، خطی را که network.host را مشخص میکند پیدا کرده و آن را با localhost به این صورت جایگزین کنید:
network.host: localhost
این حداقل تنظیماتی است که میتوانید برای استفاده از Elasticsearch با آن شروع کنید. اکنون میتوانید Elasticsearch را برای اولین بار راه اندازی کنید.
برای راه اندازی این ابزار، دستورات زیرا را وارد نمایید:
#systemctl start elasticsearch
#systemctl enable elasticsearch
با ارسال درخواست HTTP میتوانید آزمایش کنید که آیا سرویس Elasticsearch شما اجرا میشود یا خیر:
#curl -X GET “localhost:9200”
پاسخی خواهید دید که برخی از اطلاعات اولیه را در رابطه با ابزار نصب شده، نشان میدهد.
اکنون که Elasticsearch راهاندازی شده است، بیایید Kibana، جزء بعدی Elastic Stack را نصب کنیم.
مرحله ۲: نصب و پیکربندی Kibana
طبق مستندات رسمی، کیبانا را فقط پس از نصب Elasticsearch باید نصب کنید. نصب به این ترتیب تضمین میکند که اجزایی که هر محصول به آنها وابسته است به درستی در جای خود قرار دارند.
از آنجایی که قبلاً منبع بسته Elastic را در مرحله قبل اضافه کردهاید، میتوانید اجزای باقیمانده از Elastic Stack را با استفاده از apt نصب کنید:
#apt install kibana
#systemctl enable kibana
#systemctl start kibana
از آنجایی که کیبانا طوری پیکربندی شده است که فقط به لوکالهاست گوش دهد، باید یک پروکسی معکوس (Reverse Proxy) راه اندازی کنیم تا اجازه دسترسی خارجی به آن را بدهیم. ما برای این منظور از Nginx استفاده خواهیم کرد که قبلاً باید روی سرور شما نصب شده باشد.
ابتدا از دستور openssl برای ایجاد یک کاربر مدیریتی Kibana استفاده کنید که از آن برای دسترسی به رابط وب کیبانا استفاده خواهید کرد. به عنوان مثال، نام این حساب را kibanaadmin میگذاریم، اما برای اطمینان از امنیت بیشتر، توصیه میکنیم یک نام غیر استاندارد برای کاربر خود انتخاب کنید که حدس زدن آن دشوار باشد.
دستور زیر کاربر و رمز عبور کیبانا را ایجاد کرده و در فایل htpasswd.users ذخیره میکند. شما Nginx را طوری پیکربندی میکنید که به این نام کاربری و رمز عبور نیاز داشته باشد و این فایل را لحظهای بخواند:
#echo “kibanaadmin:`openssl passwd -apr1`” | sudo tee -a /etc/nginx/htpasswd.users
رمز عبور را وارد کنید و آن را تأیید کنید. این رمز را به خاطر بسپارید، زیرا برای دسترسی به رابط وب کیبانا به آن نیاز دارید. سپس یک فایل بلوک سرور Nginx ایجاد می کنیم. به عنوان مثال، ما به این فایل با عنوان your_domain اشاره می کنیم، اگرچه ممکن است برای شما مفید باشد که نام توصیفی تری برای فایل خود قرار دهید. به عنوان مثال، اگر یک رکورد FQDN و DNS برای این سرور تنظیم کرده اید، می توانید این فایل را به نام FQDN خود نام گذاری کنید.
با استفاده از vim یا ویرایشگر متن دلخواه خود، فایل بلوک سرور Nginx را ایجاد کنید:
#vim /etc/nginx/sites-available/your_domain
بلوک کد زیر را به فایل اضافه کنید، مطمئن شوید که your_domain را برای مطابقت با FQDN یا آدرس IP عمومی سرور خود به روز کنید. این کد Nginx را پیکربندی می کند تا ترافیک HTTP سرور شما را به برنامه Kibana هدایت کند که در localhost:5601 به گوش است. علاوه بر این، Nginx را برای خواندن فایل htpasswd.users و نیاز به احراز هویت اولیه پیکربندی می کند.
your_domain
server {
listen 80;
server_name your_domain;
auth_basic “Restricted Access”;
auth_basic_user_file /etc/nginx/htpasswd.users;
location / {
proxy_pass http://localhost:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection ‘upgrade’;
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
وقتی کارتان تمام شد، فایل را ذخیره و ببندید. در مرحله بعد، پیکربندی جدید را با ایجاد یک پیوند نمادین به دایرکتوری فعال شده توسط سایت ها فعال کنید. اگر قبلاً یک فایل بلوک سرور با همین نام در پیش نیاز Nginx ایجاد کرده اید، نیازی به اجرای این دستور ندارید:
#ln -s /etc/nginx/sites-available/your_domain /etc/nginx/sites-enabled/your_domain
#systemctl restart nginx
Kibana اکنون از طریق FQDN یا آدرس IP عمومی سرور Elastic Stack شما قابل دسترسی است. میتوانید صفحه وضعیت سرور کیبانا را با پیمایش به آدرس زیر و وارد کردن اعتبار ورود خود در صورت درخواست بررسی کنید:
http://your_domain/status
این صفحه وضعیت اطلاعاتی در مورد استفاده از منابع سرور نمایش می دهد و افزونه های نصب شده را فهرست می کند.
اکنون که داشبورد Kibana پیکربندی شده است، اجازه دهید مؤلفه بعدی را نصب کنیم: Logstash.
مرحله ۳: نصب و پیکربندی Logstash
اگرچه ممکن است Beats داده ها را مستقیماً به پایگاه داده Elasticsearch ارسال کند، اما استفاده از Logstash برای پردازش داده ها معمول است. این به شما امکان انعطاف پذیری بیشتری را برای جمع آوری داده ها از منابع مختلف، تبدیل آن به یک فرمت مشترک و دادن آن به پایگاه داده دیگر را می دهد.
Logstash را با این دستور نصب کنید:
#apt install logstash
پس از نصب Logstash، می توانید به سراغ پیکربندی آن بروید. فایل های پیکربندی Logstash در پوشه /etc/logstash/conf.d قرار دارند. برای اطلاعات بیشتر در مورد نحو پیکربندی، می توانید مرجع پیکربندی که Elastic ارائه می دهد را بررسی کنید. همانطور که فایل را پیکربندی میکنید، مفید است که Logstash را بهعنوان خط ارتباطی در نظر بگیرید که دادهها را میگیرد، آنها را به روشی پردازش میکند و به مقصد میفرستد (در این مورد، مقصد Elasticsearch است). یک خط ارتباطی Logstash دارای دو عنصر ضروری، ورودی و خروجی، و یک عنصر اختیاری، فیلتر است. پلاگین های ورودی داده ها را از یک منبع مصرف می کنند، پلاگین های فیلتر داده ها را پردازش می کنند و افزونه های خروجی داده ها را به مقصد می فرستند.
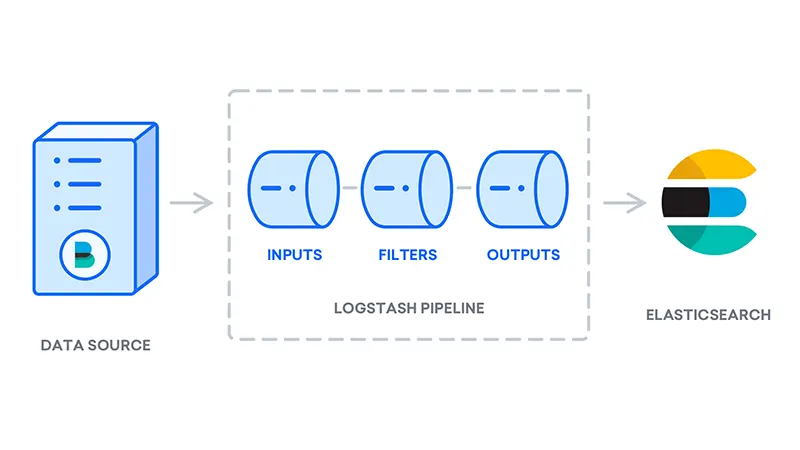
یک فایل پیکربندی به نام ۰۲-beats-input.conf ایجاد کنید که در آن ورودی Filebeat خود را تنظیم کنید:
#vim /etc/logstash/conf.d/02-beats-input.conf
پیکربندی ورودی زیر را وارد کنید. این یک ورودی بیتی را مشخص می کند که به پورت TCP 5044 گوش می دهد.
۰۲-beats-input.conf
input {
beats {
port => 5044
}
}
سپس یک فایل پیکربندی به نام ۳۰-elasticsearch-output.conf ایجاد کنید:
#vim /etc/logstash/conf.d/30-elasticsearch-output.conf
پیکربندی خروجی زیر را وارد کنید. اساساً، این خروجی Logstash را پیکربندی میکند تا دادههای Beats را در Elasticsearch که در localhost:9200 اجرا میشود، در فهرستی به نام بیت ذخیره کند. بیت مورد استفاده در این آموزش Filebeat است:
۳۰-elasticsearch-output.conf
تنظیمات Logstash خود را با این دستور تست کنید:
#sudo -u logstash /usr/share/logstash/bin/logstash –path.settings /etc/logstash -t
اگر هیچ خطایی وجود نداشته باشد، خروجی شما نتیجه Config Validation Result: OK. Exiting Logstash را نمایش می دهد. اگر این مورد را در خروجی خود نمی بینید، خطاهای ذکر شده در خروجی خود را بررسی کنید و پیکربندی خود را برای اصلاح آنها به روز کنید. توجه داشته باشید که اخطارهایی از OpenJDK دریافت خواهید کرد، اما نباید مشکلی ایجاد کنند و می توان آنها را نادیده گرفت.
اگر تست پیکربندی شما موفقیت آمیز بود، Logstash را شروع و فعال کنید تا تغییرات پیکربندی را اعمال کند:
#systemctl start logstash
#systemctl enable logstash
اکنون که Logstash به درستی اجرا می شود و به طور کامل پیکربندی شده است، اجازه دهید Filebeat را نصب کنیم.
مرحله ۴: نصب و پیکربندی Filebeat
Elastic Stack از چندین ارسال کننده داده سبک وزن به نام Beats برای جمع آوری داده ها از منابع مختلف و انتقال آنها به Logstash یا Elasticsearch استفاده می کند. در اینجا بیت هایی که در حال حاضر از Elastic در دسترس هستند آمده است:
- Filebeat: برای جمع آوری داده ها از فایل های متنی، فایل های JSON و سایر فرمت های فایل استفاده می شود.
- Metricbeat: برای جمع آوری داده های مربوط به عملکرد از سیستم عامل، برنامه ها و زیرساخت ها استفاده می شود.
- Packetbeat: برای جمع آوری داده های مربوط به شبکه، مانند ترافیک HTTP، ترافیک TCP و ترافیک UDP استفاده می شود.
- Winlogbeat: برای جمع آوری داده های مربوط به سیستم عامل ویندوز، مانند رویدادهای سیستم، رویدادهای برنامه و رویدادهای امنیتی استفاده می شود.
- Auditbeat: برای جمع آوری داده های مربوط به امنیت، مانند رویدادهای ورود به سیستم، رویدادهای استفاده از حساب و رویدادهای تغییر تنظیمات استفاده می شود.
- Heartbeat: برای نظارت بر سلامت سیستم ها و زیرساخت ها استفاده می شود.
در این آموزش ما از Filebeat برای ارسال گزارش های محلی به Elastic Stack خود استفاده خواهیم کرد.
Filebeat را با استفاده از apt نصب کنید:
#apt install filebeat
در مرحله بعد، Filebeat را برای اتصال به Logstash پیکربندی کنید. در اینجا، فایل پیکربندی نمونه ای را که همراه با Filebeat ارائه می شود، اصلاح می کنیم.
فایل پیکربندی Filebeat را باز کنید:
#vim /etc/filebeat/filebeat.yml
توجه: مانند Elasticsearch، فایل پیکربندی Filebeat در قالب YAML است. این به این معنی است که تورفتگی مناسب بسیار مهم است، بنابراین حتما از همان تعداد فاصله هایی که در این دستورالعمل ها مشخص شده است استفاده کنید.
Filebeat از خروجی های متعددی پشتیبانی می کند، اما معمولاً رویدادها را مستقیماً به Elasticsearch یا Logstash برای پردازش اضافی ارسال می کنید. در این آموزش، ما از Logstash برای انجام پردازش های اضافی روی داده های جمع آوری شده توسط Filebeat استفاده می کنیم. Filebeat نیازی به ارسال مستقیم هیچ داده ای به Elasticsearch ندارد، بنابراین اجازه دهید آن خروجی را غیرفعال کنیم. برای انجام این کار، بخش output.elasticsearch را بیابید و خطوط زیر را با علامت # قبل از آنها کامنت کنید:
filebeat.yml
#Array of hosts to connect to.
#hosts: [“localhost:9200”]
سپس قسمت output.logstash را پیکربندی کنید. خطوط output.logstash: و میزبان ها: [“localhost:5044”] را با حذف # از حالت کامنت خارج کنید. با این کار Filebeat برای اتصال به Logstash در سرور Elastic Stack شما در پورت ۵۰۴۴، پورتی که قبلا یک ورودی Logstash را برای آن مشخص کرده بودیم، پیکربندی میکند:
filebeat.yml
# The Logstash hosts
hosts: [“localhost:5044”]
عملکرد Filebeat را می توان با ماژول های Filebeat گسترش داد. در این آموزش ما از ماژول سیستم استفاده می کنیم که گزارش های ایجاد شده توسط سرویس ثبت سیستم توزیع های رایج لینوکس را جمع آوری و تجزیه می کند. پس بیایید آن را فعال کنیم:
#filebeat modules enable system
با اجرای دستور زیر می توانید لیستی از ماژول های فعال و غیرفعال را مشاهده کنید:
#filebeat modules list
به طور پیشفرض، Filebeat برای استفاده از مسیرهای پیشفرض برای گزارشهای syslog و مجوز پیکربندی شده است. در مورد این آموزش، شما نیازی به تغییر چیزی در تنظیمات ندارید. شما می توانید پارامترهای ماژول را در فایل پیکربندی /etc/filebeat/modules.d/system.yml مشاهده کنید.
در مرحله بعد، باید خطوط مسیر دریافت Filebeat را راهاندازی کنیم، که دادههای گزارش را قبل از ارسال از طریق logstash به Elasticsearch تجزیه میکنند. برای بارگیری مسیر ورودی برای ماژول سیستم، دستور زیر را وارد کنید:
#filebeat setup –pipelines –modules system
سپس، قالب ایندکس را در Elasticsearch بارگذاری کنید. فهرست Elasticsearch مجموعه ای از اسناد است که دارای ویژگی های مشابه هستند. ایندکس ها با یک نام شناسایی می شوند که برای اشاره به شاخص هنگام انجام عملیات مختلف در داخل آن استفاده می شود. هنگامی که یک نمایه جدید ایجاد می شود، الگوی فهرست به طور خودکار اعمال می شود.
برای بارگذاری قالب از دستور زیر استفاده کنید:
#filebeat setup –index-management -E output.logstash.enabled=false -E ‘output.elasticsearch.hosts=[“localhost:9200”]’
Filebeat همراه با نمونه داشبورد Kibana است که به شما امکان می دهد داده های Filebeat را در Kibana تجسم کنید. قبل از اینکه بتوانید از داشبوردها استفاده کنید، باید الگوی شاخص ایجاد کنید و داشبوردها را در کیبانا بارگذاری کنید.
با لود شدن داشبوردها، Filebeat به Elasticsearch متصل می شود تا اطلاعات نسخه را بررسی کند. برای بارگیری داشبوردها زمانی که Logstash فعال است، باید خروجی Logstash را غیرفعال کنید و خروجی Elasticsearch را فعال کنید:
#filebeat setup -E output.logstash.enabled=false -E output.elasticsearch.hosts=[‘localhost:9200’] -E setup.kibana.host=localhost:5601
پس از چند دقیقه، باید خروجی مشابه زیر دریافت کنید:
Output
Overwriting ILM policy is disabled. Set `setup.ilm.overwrite:true` for enabling.
Index setup finished.
Loading dashboards (Kibana must be running and reachable)
Loaded dashboards
Setting up ML using setup –machine-learning is going to be removed in 8.0.0. Please use the ML app instead.
See more: https://www.elastic.co/guide/en/elastic-stack-overview/current/xpack-ml.html
Loaded machine learning job configurations
Loaded Ingest pipelines
اکنون می توانید Filebeat را استارت و فعال کنید:
#systemctl start filebeat
#systemctl enable filebeat
اگر Elastic Stack خود را به درستی تنظیم کرده باشید، Filebeat شروع به ارسال گزارش های syslog و مجوز شما به Logstash می کند، که سپس آن داده ها را در Elasticsearch بارگیری می کند.
برای تأیید اینکه Elasticsearch واقعاً این داده ها را دریافت می کند، فهرست Filebeat را با این دستور جستجو کنید:
#curl -XGET ‘http://localhost:9200/filebeat-*/_search?pretty’
مرحله ۵: کاوش در داشبورد کیبانا
بیایید به رابط وب کیبانا که قبلاً نصب کرده بودیم برگردیم. در یک مرورگر وب، به FQDN یا آدرس IP عمومی سرور Elastic Stack خود بروید. اگر session شما قطع شده است، باید مجدداً اطلاعات کاربری را که در مرحله ۲ تعریف کرده اید وارد کنید. پس از ورود به سیستم، باید صفحه اصلی Kibana را دریافت کنید.
روی پیوند Discover در نوار پیمایش سمت چپ کلیک کنید (برای دیدن موارد منوی پیمایش، ممکن است مجبور شوید روی نماد گسترش در پایین سمت چپ کلیک کنید). در صفحه Discover، الگوی از پیش تعریف شده filebeat-* را انتخاب کنید تا داده های Filebeat را ببینید. بهطور پیشفرض، تمام دادههای گزارش در ۱۵ دقیقه گذشته را به شما نشان میدهد. یک هیستوگرام با رویدادهای گزارش و برخی از پیامهای گزارش مشاهده خواهید کرد.
در اینجا، می توانید در لاگ های خود جستجو و مرور کنید و همچنین داشبورد خود را سفارشی کنید. با این حال، در این مرحله، چیز زیادی در آنجا وجود نخواهد داشت زیرا شما فقط در حال جمع آوری syslog از سرور Elastic Stack خود هستید.
از پانل سمت چپ برای رفتن به صفحه داشبورد و جستجوی داشبوردهای Filebeat System استفاده کنید. پس از آن، می توانید داشبوردهای نمونه همراه با ماژول سیستم Filebeat را انتخاب کنید.
Kibana دارای بسیاری از ویژگی های دیگر مانند نمودار و فیلتر کردن است، بنابراین به جستجوی خود در این داشبورد ادامه دهید.




