فهرست مطالب
Big Data چیست؟
یکی از اجزای اصلی پلتفرم ۳، بیگ دیتا است. کلمه ی بیگ دیتا، یک اصطلاح جدید می باشد که در دهه اخیر زیاد شنیده می شود و در Platform 3 بسیار مورد توجه قرار می گیرد. این اصطلاح برای مجموعه داده های حجیم که بزرگ، متنوع، با ساختار پیچیده و با دشواری هایی برای ذخیره سازی و تجزیه و تحلیل نتایج می باشد، بکار می رود. پروسه تحقیق بر روی داده های حجیم، جهت آشکارسازی الگوهای مخفی و راز همبستگی ها، تجزیه و تحلیل big data نامیده می شود. این اطلاعات مفید برای سازمانها و شرکتها در جهت کسب بینش غنی تر و عمیق تر و موفقیت در رقابت کمک می کند.
معمولا Big data را بصورت سه V تعریف می کنند (یعنی سه مشخصه اصلی که با حرف V انگلیسی آغاز می گردند) که شامل این موارد می شود: حجم (Volume) ، سرعت (Velocity) ، تنوع (Variety)
حجم:
عبارت Big در اینجا اشاره به وجود حجم عظیم داده ها دارد. فاکتورهای بسیاری به افزایش حجم داده ها کمک می کند. سازمانها در این سال ها شاهد رشد فزاینده داده ها در همه انواع مختلف هستند مانند داده های بر پایه تراکنش ذخیره شده در طی سالیان، داده های غیرساختاریافته سرازیر شده از رسانه های اجتماعی؛ مقدار در حال افزایش داده های ماشین-به-ماشین و سنسور جمع آوری شده. حجم این داده ها در سال های اخیر از ترابایت عبور کرده و به پتابایت و حتی اگزابایت نیز رسیده است.
۲۶ سال از زمانی که بیل گیتس مجبور شد برای نشان دادن بزرگی ۷۰۰ مگابایت عکس زیر را منتشر کند، میگذرد و اکنون مشاهده میکنید سرعت رشد فناوری به گونهای بوده که به ظرفیت اگزابایت نیز رسیدهایم و مطمئناً در آینده اگزابایت نیز برای ما بسیار کوچک خواهد بود.

در گذشته، مسئله ذخیره سازی این حجم انبوه اطلاعات بسیار مهم بود اما با کاهش هزینه های ذخیره سازی، مسائل دیگری سر بر می آورند؛ شامل چگونگی تعیین ارتباط در حجم زیاد داده ها و چگونگی استفاده از علم تجزیه و تحلیل به منظور ایجاد ارزش از داده های مرتبط.
سرعت:
داده ها با سرعتی بی سابقه وارد شده و باید در زمان مناسب به سراغ آنها رفت. تگ های RFID، سنسورها و اندازه گیری هوشمند، نیاز به سر و کله زدن با جریانات داده را در اولین زمان نزدیک به اکنون را ایجاد می کنند. واکنش سریع در کار با داده ها، چالشی برای بیشتر سازمان هاست. برای مثال دوربین های تشخیص چهره در فرودگاه ها را در نظر بگیرید که نیاز به سرعت عمل و دریافت نتیجه آنی در آن بسیار ضروری است.
تنوع:
داده ها به شکل های گوناگونی وارد می شوند. داده های عددی ساختاریافته در پایگاه های داده سنتی؛ اطلاعات ایجاد شده از برنامه های کاربردی کسب وکار؛ اسناد متنی غیرساختاریافته، ایمیل، صدا و تراکنش های مالی. مدیریت، ادغام و تحلیل بر انواع گوناگون داده، چیزی است که بسیاری از سازمان ها هنوز با آن درگیرند و یک نیاز ضروری برای آنها است. برای مثال یک مرکز پزشکی را در نظر بگیرید که در رابطه با یک بیمار به خصوص، می بایست تعداد زیادی از تمامی سوابق تغییرات حال او، با تحقیقات پزشکی مختلف منتشر شده، تحلیل گردد و در نتیجه آن، بهترین درمان برای او تجویز شود.
اهمیت Big Data در چیست؟
در اینجا بحث اصلی این نیست که حجم زیادی از دیتا را بدست آورید؛ این است که با آن حجم عظیم چه می کنید. دیدگاه امیدوارانه این است که سازمان ها قادر به تحصیل داده از هر منبعی بوده، داده های مرتبط را تهیه کرده و آن را تحلیل کنند تا این نتایج حاصل شوند: ۱)کاهش هزینه ها، ۲)کاهش زمان، ۳)توسعه محصولات جدید و پیشنهادات جدید، و ۴) تصمیم گیری هوشمندانه تر . برای مثال، با ترکیب Big Data و تحلیل های قوی، این امکان وجود دارد تا:
- علت های اصلی شکست ها، مسائل و نقوص را در لحظه تعیین کرد، تا سالانه بتوان میلیون ها دلار در سازمان های بزرگ صرفه جویی کرد.
- مسیر وسیله های حمل بسته های تحویلی را زمانی که هنوز در جاده هستند، بهینه کرد.
- در چند ثانیه تمام سبد ریسک را دوباره حساب کرد.
- سریعاً مشتریانی که بیشترین اهمیت را دارند، شناسایی کرد.
مخازن داده
داده ها برای تحلیل معمولا از دو منبع وارد می شوند:
انبار داده (Data Warehouse)
انـبـار داده که یک مخزن مرکزی است، بـه مجـموعـهای از دادههــا گفـتـه میشود که از منابع مختلف اطلاعاتی سازمان جمعآوری، دستهبندی و ذخیره میشود. تمامی این داده ها بصورت ساختاریافته (Structured data) است.
انبار داده یا Data Warehouse پایگاه دادهای است که برای گزارشگیری و تحلیل داده به کار میرود و بعنوان هسته اصلی یک سیستم BI به شمار میآید. به عبارت دیگر انبار داده یک مخزن داده مرکزی از دادههای تجمیع شده است که از سیستمها و منابع مختلف سازمان جمعآوری شده است.
دریاچه داده (Data Lake)
امروزه انواع جدیدی از دادهها به شکل فزاینده ای در حال شکلگیری هستند. دادههایی که توسط وبسایتهای سازمانها، صفحات شبکههای اجتماعی، سنسورها و دستگاههای متصل به وب، اطلاعات مسیرهای حرکتی با دستگاههای GPS و بطور عمومی اینترنت اشیاء (IoT) و شبکههای اجتماعی یا سازوکارهای نظیر آنها ایجاد می شوند، این پرسش را به وجود آوردهاند که آیا اساساً استفاده از فناوری «انبار داده» به منظور ذخیره و تحلیل این اطلاعات از اثربخشی لازم برخوردارند یا خیر.
یکی از موضوعاتی که در تحلیل انواع جدید دادهها اهمیت دارد، حجم بالایی از دادههاست که با سرعتی سرسامآور رشد میکنند و مدلهای ذخیرهسازی و تحلیلهای مبتنی بر رایانههای منفرد، پاسخگوی آنها نیستند. از طرفی توسعه پلتفرمهای مختلف ذخیرهسازی دادهها مانند فایل سیستمهای توزیعشده در دادههای بزرگ (مانند Hadoop) یا سیستمهای ذخیره سازی ابری (مانند Amazon S۳) که انواع مختلفی از دادههای ساختار یافته یا غیر ساختاریافته را در خود ذخیره میکنند و لزوم تحلیل دقیق و سریع آنها، مدل انبار داده سنتی را به صورت جدی به چالش کشیده است.
مفهوم دریاچه داده (Data lake) در پاسخگویی به نیاز مذکور به تدریج توسعه پیدا کرده است. به منظور تشریح این مفهوم از تمثیلی استفاده میکنیم، اگر انبار داده را مشابه یک بطری آب تصفیهشده، بستهبندی شده و آماده مصرف در نظر بگیریم دریاچه داده (همانند نام آن) دریاچهای است که آب از منابع مختلف ( آب باران، چشمه ها، رودها یا منابع دیگر) در آن سرازیر شده و افراد میتوانند از آب دریاچه برای شنا، آشامیدن یا حتی نمونهبرداری! استفاده کنند.
دادهها کاملاً در دریاچه داده قرار میگیرند و از هیچ دادهای صرفنظر نمیشود. این رویکرد برخلاف رویکرد انبار داده در ذخیرهسازی و پالایش دادهها است که در آن تنها اطلاعاتی در انبار داده قرار میگیرد که بتواند در تحلیلها مورد استفاده قرار گیرد. همچنین دادههای پایینترین سطوح بدون تغییر یا با حداقل تغییرات به دریاچه داده منتقل میشوند که این مهم، برخلاف رویکرد انبار داده است که تبدیل و تغییر (Transformation) یکی از پیشفرضهای اساسی و اولیه ورود اطلاعات به آن محسوب میشود.
اجزاء اصلی Big Data
همانطور که گفته شد بیگ دیتا، دیتای بسیار بزرگی است که از طریق روش های سنتی نمی توان آنرا پردازش کرد. سازندگان موتورهای جستجو، اولین کسانی بودند که با این چالش روبرو شدند و در ادامه، شبکه های اجتماعی، تلفن های موبایل و سایرین نیز با آن روبرو شدند. برای برطرف کردن چالش دیتاهای بزرگ، برای اولین بار گوگل MapReduce را ساخت. همانطور که محبوبیت MapReduce بیشتر می شد، یک مجموعه لایه ها برای بیگ دیتا ظهور کرد که آنرا با نام SMAQ می شناسیم.
SMAQ Stack = Storage, MapReduce, Query
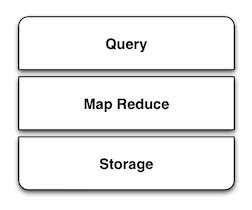
همانطور که رشته LAMP که متشکل از لینوکس، آپاچی، Mysql و PHP بود و چشم انداز نرم افزارهای تحت وب را بکلی تغییر داد، رشته SMAQ نیز تغییر شگرفتی در پردازش و ذخیره سازی داده های بزرگ ایجاد کرد. تمامی این سه راهکار در ادامه به تفکیک توضیح داده خواهند شد.
راهکار MapReduce
MapReduce، یک مدل برنامه نویسی ساده است که برای حل مسائل محاسباتی در مقیاس وسیع و نیز به صورت توزیعی، مورد استفاده قرار میگیرد. مفهوم MapReduce برای اولین بار توسط گوگل در سال ۲۰۰۳ ارائه شد. MapReduce یک چارچوب نرمافزاری است که بستری امن و مقیاس پذیر برای توسعه کاربردهای توزیعی فراهم میکند و به زبانهای مختلف پیادهسازی شده است.
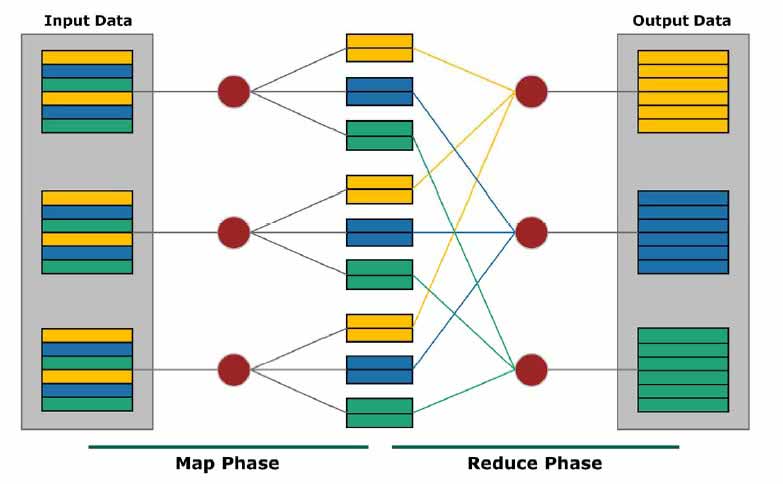
این framework چالش اصلی پردازش داده های بسیار بزرگ را که قبل از این می بایست تنها توسط یک ماشین انجام می شد را حل کرده و با تقسیم این بار بین چندین ماشین، کار پردازش دیتا را بسیار سریعتر و راحتتر کرده است.
در واقع MapReduce مجموعه ای از توابع کتابخانه را در دل خود دارد که جزئیات و پیچیدگی را از دید برنامهنویس پنهان میکند. جزئیات این framework شامل موارد زیر میشود:
- موازی سازی کارها به صورت خودکار
- تعادل در بار محاسباتی و داده
- بهینه سازی در انتقالات دیسک و شبکه
- اداره کردن نقصهای رخ داده در ماشینها
برای اینکه متوجه شوید MapReduce چگونه کار می کند، به دو بخش موجود در نام آن توجه نمایید. در اینجا دو گام اصلی به نام Map و Reduce وجود دارد.
گام Map: گره اصلی، ورودی را گرفته و آن را به زیر مسائل کوچکتری تقسیم میکند. سپس آنها را بین گرههایی که وظیفه انجام کارها را دارند، توزیع میکند. ممکن است این نود نیز همین کار را تکرار کند که در این حالت یک ساختار چند سطحی داریم. در نهایت این زیر مسائل پردازش شده و پاسخ به گره اصلی ارسال میشود.
گام Reduce: حال، گره اصلی که پاسخ ها و نتایج را دریافت کرد، آنها را برای ارائه خروجی، ترکیب میکند. در این میان ممکن است اعمالی مانند فیلتر کردن، خلاصه کردن و یا تبدیل کردن، بر روی نتایج انجام دهد.
راهکار آپاچی هادوپ (Apache Hadoop)
هادوپ توسط Doug Cutting سازنده Apache Lucene که بصورت گسترده برای عمیات جستجوی متن ها استفاده می شود، تولید شد. در حقیقت به وجود آمدن هادوپ از کار بر روی Nutch شروع شد. Apache Nutch یک فریم ورک متن باز برای ایجاد موتور جستجو است که بصورت گسترده، عملیات جستجوی متن ها را به روشی که Crawling نام گرفت انجام می دهد.
برای شروع، Doug و همکارش مایک ایده ساختن یک موتور جستجوگر وب را در سر داشتند اما این تنها چالش آنها نبود، قیمت سخت افزار یک موتور جستجوگر که ۱ میلیون صفحه وب را جستجو و ایندکس می کند در حدود پانصد هزار دلار بود با این وجود آنها باور داشتند که این پروژه یک هدف ارزشمند است.
طی زمانی، معماران پروژه دریافتند که این پروژه قابلیت و توانایی کار کردن با میلیونها صفحه وب را ندارد، در همان برهه در سال ۲۰۰۳ مقاله ای از شرکت گوگل منتشر شد که توانست راهگشای مشکل آنها باشد و معماری Google file system را توصیف می کرد. GFS توانست مشکل ذخیره سازی داده های عظیم را حل کند. یکسال بعد تیم nutch نسخه متن باز خود را با نام NDFS منتشر کرد.
در سال ۲۰۰۴ گوگل با مقاله ای MapReduce را به جهان معرفی کرد، خیلی زود در سال ۲۰۰۵ برنامه نویسان Nutch شروع به کار با آن کردند و تا اواسط همان سال نسخه جدید خود را که با NDFS کار می کرد به جهان معرفی کرد. بعد از چندی آنها دریافتند که عملکرد آن فراتر از فقط یک موتور جستجوگر است و در فوریه ۲۰۰۶ آنها از پروژه Nutch که خود زیر پروژه Lucine به حساب می آمد به سمت پروژه ای آمدند که آن را Hadoop (هادوپ) نامیدند. در تقریبا همان سال Doug به یاهو پیوست تا با استفاده از یک تیم مستقل هادوپ را آزمایش و پیاده سازی کند.
در سال ۲۰۰۸ شرکت یاهو ، موتور جستجویی را معرفی کرد که توسط ۱۰۰۰۰ کلاستر هادوپ عملیات جستجو را انجام می داد. در همان سال و در ماه ژانویه هادوپ در بالاترین سطح پروژه های آپاچی قرار گرفت در آن زمان دیگر تنها یاهو تنها استفاده کننده این محصول نبود، شرکتهایی نظیر فیسبوک و نیویورک تایمز نیز شروع به فعالیت در این حوزه کرده بودند.
در آوریل سال ۲۰۰۸ هادوپ رکورد جهان را شکست و سریعترین سیستمی شد که توانست ۱ ترابایت داده را ظرف ۲۰۲ ثانیه و با استفاده از ۹۱۰ نود کلاستر پردازش کند. این رکورد در سال قبل با ۲۹۷ ثانیه ثبت شده بود. در نوامبر همان سال گوگل طی گزارشی اعلام کرد که این رکورد را به ۶۸ ثانیه ارتقاء داده است. در آوریل ۲۰۰۹ یاهو اعلام کرد با استفاده از هادوپ توانسته ۱ ترابایت داده را ظرف ۶۲ ثانیه پردازش کند. و بالاخره در سال ۲۰۱۴ یک تیم از شرکت DataBricks اعلام کرد که توانسته با استفاده از ۲۰۷ نود کلاستر اسپارک حدود ۱۰۰ ترابایت داده را ظرف ۱۴۰۶ ثانیه که تقریبا ۴.۲۷ ترابایت در دقیقه می شود پردازش کند.
امروزه هادوپ بصورت وسیعی و در زمینه های بسیاری از فعالیتهای دانشگاهی تا تجارت، از علوم تا نجوم مورد استفاده قرار می گیرد. هادوپ مکانی امن برای ذخیره و تحلیل داده های کلان بشمار می رود ، مقیاس پذیر، توسعه پذیر و متن باز است . هادوپ هدف اصلی کمپانی های بزرگ تولید و ذخیره داده ها از جمله فیسبوک، آی بی ام، EMC ، اوراکل و مایکروسافت است.
بطور خلاصه، هادوپ یک فریم ورک یا مجموعه ای از نرم افزارها و کتابخانه هایی است که ساز و کار پردازش حجم عظیمی از داده های توزیع شده را فراهم میکند. در واقع هادوپ را می توان به یک سیستم عامل تشبیه کرد که طراحی شده تا بتواند حجم زیادی از داده ها را بر روی ماشین های مختلف پردازش و مدیریت کند. فریم ورک هادوپ شامل زیر پروژه های مختلفی می شود که در زیر لیست کامل آنها آمده است:
HDFS – YARN – MapReduce – Ambari – Avro – Cassandra – Chukwa – HBase -Hive – Mahout – Pig – Spark – Tez – Zookeeper
لایه Storage
بعد از اینکه MapReduce پردازش خود را بر روی دیتا انجام داد، نتایج حاصل می بایست در Storage ذخیره شوند. طراحی و ویژگی های لایه استوریج بسیار مهم است به این دلیل که راحتی کار را برای لود کردن دیتا و استخراج و جستجوی نتایج محاسبات، به همراه خواهد داشت.
یک سیستم استوریج در SMAQ stack بر مبنای یک فایل سیستم اختصاصی متن باز مانند فایل سیستم هادوپ (HDFS) است و یا اینکه ممکن است برای دسترسی کاربران از چندین فایل سیستم استفاده نماید. یک سیستم استوریج شامل چندین نود می باشد که مجموعا به همه آنها Cluster می گویند و فایل سیستم در بین همه نودها توزیع شده است. هر نود علاوه بر اینکه ظرفیت ذخیره سازی دارد، برای خود توانایی پردازش نیز دارد. این سیستم دارای معماری با مقیاس پذیری بالا است بدین صورت که نودهای اضافی بصورت کاملا پویا به سیستم اضافه شده تا احتیاجات مربوط به ظرفیت و تقسیم بار کاری را برطرف سازد.
فایل سیستم HDFS مانند سایر فایل سیستم های عادی فقط یک رابط عادی را فراهم می کند. برخلاف دیتابیس، دیتا را فقط ذخیره و بازیابی می کند و index نمی کند، که برای بازیابی سریع دیتا ضروری است. برای این منظور و همچنین به دست آوردن مزیت های دیتابیس، راه کار SMAQ از یک NoSQL database در بالای فایل سیستم خود استفاده می کند. این No-SQL ویژگی های MapReduce را در داخل خود دارد که اجازه می دهد پردازش ها بر روی دیتای ذخیره شده بصورت موازی انجام گردد. در خیلی از برنامه ها ورودی اصلی دیتا بصورت پایگاه داده رابطه ای می باشد، بنابراین راهکار SMAQ این نوع از دیتاها را نیز پشتیبانی می کند.
لایه Query
بصورت خیلی خلاصه برای ساده کردن وظایف MapReduce و تحلیل نتایج از یک لایه بالاتر به نام Query استفاده می شود که امکان اجرا و مانیتورینگ وظایف MapReduce را از طریق یک رابط کاربری به ما می دهد. چندین نمونه از محصولات این لایه بصورت تجاری و یا Open source عرضه شده اند، مانند Pig که توسط یاهو توسعه داده شده است و هم اکنون قسمتی از پروژه هادوپ است و یا Hive که توسط فیسبوک عرضه شده است.