فهرست مطالب
مقدمه ای بر پلتفرم OpenStack
OpenStack چیست؟ مجموعهای از ابزارهای نرم افزاری و یک پلتفرم متن باز برای راهاندازی براساس معماری IaaS بهصورت private cloud و یا public cloud میباشد و رقیبی بسیار جدی برای VMware vCloud است و بسیاری معتقدند که آینده رایانش ابری در اختیار این محصول است. غولهایی مانند Intel، Wikipedia و Paypal از پلتفرم اپن استک استفاده میکنند که توسط یک موسسه غیرانتفاعی بهنام OpenStack Foundation مدیریت میشود. openstack که از جهاتی بسیار شبیه AWS آمازون و Azure مایکروسافت است، از طریق یک داشبورد مدیریت میشود که کاربران را قادر میسازد منابع را از طریق یک رابط وب مدیریت کنند. اپن استک برای توسعه از نوع Horizontal Scaling طراحی شده است که اجازه میدهد همهی سرویسها بهطور بسیار گستردهای قابل توسعه باشند.
هایپروایزر یکی از اجزای این پلتفرم است و باید بدانید که openstack هیچ هایپروایزری بهصورت اختصاصی برای خود ندارد و از سایر هایپروایزرها مانند KVM، ESXi و HyperV پشتیبانی مینماید.
در ادامه اجزا و سرویسهای مختلف OpenStack شرح داده خواهند شد.
Nova
Nova چیست؟ موتور اصلی و یکی از پروژههای اصلی در OpenStack است که به زبان پایتون نوشته شده است و وظیفه پیادهسازی و نگهداری instance ها را بر عهده دارد. به عبارت دیگر وظیفه provision کردن compute برعهدهی Nova است که در نتیجه آن، ماشینهای مجازی ساخته میشوند.
Swift
Swift چیست؟ این پروژه اپن سورس تمرکز خود را بر روی استوریج و نحوه ذخیره سازی دیتا گذاشته است و به جای استفاده از روش سنتی Block Storage از روش Object Storage بهره میبرد و مدیریت آن را به OpenStack واگذار میکند. موارد رایج استفاده از swift شامل استوریج، بکاپ و آرشیو unstructured data مانند اسناد، عکسها، فیلمها، ماشینهای مجازی و ایمیلها است.
نحوه عملکرد آن اینگونه است که swift، دیتا را بهصورت binary object در فایل سیستم تعریف شده در سیستم عامل ذخیره میکند و هر object نیز متادیتای مربوط به خود را دارد. در معماری swift یک proxy server و نودهای استوریج وجود دارند. در پراکسی سرور انواع API برای انتقال درخواستهای خواندن و نوشتن بین client و storage و از طریق پروتکل http پیاده سازی شده است.
Cinder
Cinder چیست؟ این پروژه که یک Software define storage است بهصورت Block Storage کار میکند که در نتیجه آن سرعت خواندن و نوشتن دیتا را بسیار بالا میبرد.
Neutron
Neutron چیست؟ یک پروژه SDN است که تمرکز آن بر روی ارائه Networking-as-a-service در یک محیط مجازی سازی شده است و شامل مجموعهای از APIها، نرم افزارها و پلاگینهای مختلف است که هر کدام کار مخصوصی را انجام میدهند. به عبارت دیگر Neutron قابلیت شبکه سازی را برای اپن استک فراهم میکند تا اجزای سیستم بتوانند به سرعت و راحتی با هم ارتباط داشته باشند. این پروژه در ابتدا Quantum نامیده میشد که در ادامه به دلیل تشابه اسمی با محصولی در رابطه با tape-backup و مشکلات تجاری که ایجاد شده بود به Neutron تغییر نام داده شد.
هسته Neutron API از لایه ۲ و IPAM پشتیبانی مینماید و نیز یک extension برای پشتیبانی از لایه ۳ و ارتباط با گیتویهای خارجی برای آن وجود دارد. البته تا قبل از اینکه این پروژه اجرایی شود از یک زیرمجموعه در Nova برای شبکه سازی استفاده میشد که بهدلیل ادغام compute و network در هم، کار را کمی برای طراحان این پروژه سخت میکرد. البته همچنان میتوان در زمان راه اندازی از neutron استفاده نکرد و از ویژگی شبکه Nova بهره جست. اما اگر میخواهید از ویژگیهایی مانند HA Proxy Load Balancer و یا VPN استفاده نمایید باید حتماً به سمت Neutron بروید.
تمامی Tenantها با استفاده از Neutron قادرند چندین private network برای خود ساخته آی پیهای آنها را مدیریت نمایند و در ادامه قادرند با استفاده از API extensionها کنترلهای اضافهتری بر روی امنیت، QoS، مانیتورینگ و رفع مشکلات داشته باشند مانند راهاندازی فایروال، intrusion detection و VPN.
در زیر میتوانید لیستی از بعضی از مهمترین پلاگینهای Neutron را مشاهده نمایید:
- NEC OpenFlow
- Open vSwitch
- Cisco switches (NX-OS)
- Linux Bridging
- VMware NSX
- Juniper OpenContrail
- Ryu network OS
- PLUMgrid Director plugin
- Midokura Midonet plugin
- OpenDaylight plugin
Horizon
هورایزن چیست؟ داشبورد مدیریتی و مبتنی بر وب اپن استک است و احتمالاً اولین چیزی است که ادمین شبکه در زمان پیکربندی اپن استک خواهد دید.
Keystone
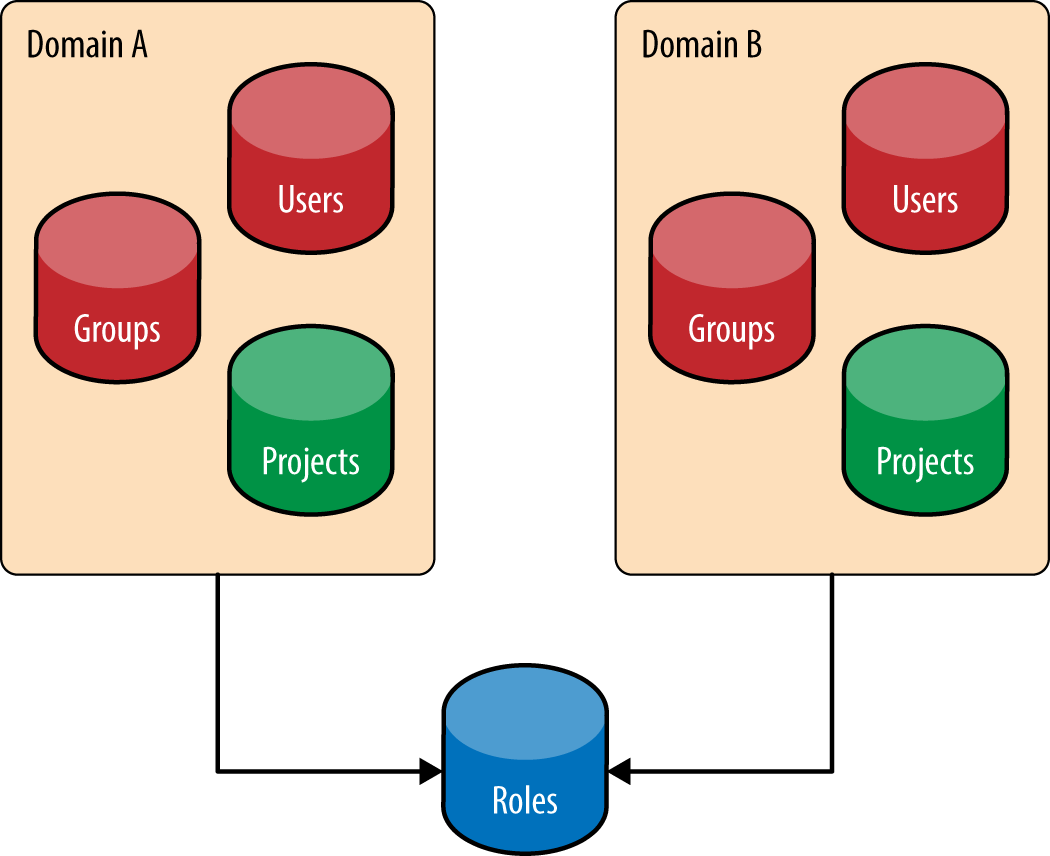
Keystone چیست؟ یکی از سرویسهای اپن استک است که وظیفه آن مدیریت دسترسی کاربران به منابع سیستمی است. تمامی منابع موجود در cloud در مفهوم انتزاعی به نام Project قرار میگیرند و در ادامه سطح دسترسی کاربران و گروهها را به Projectها تعیین میکنیم. اما در آن زمانی که اپن استک تازه پا به عرصه گذاشته بود مشکل دیگری وجود داشت و آن اینکه اگر دو سازمان در ابر شما از یک نام کاربری یکسان استفاده میکردند، بهراحتی میتوانستند به Projectهای یکدیگر دسترسی داشته باشند که این یک مشکل امنیتی بزرگ بود. در نتیجه مفهوم Domain نیز برای رفع این مشکل ایجاد شد. مکانیسم دومین باعث میشود که دیده شدن یک Project تنها به کاربران آن سازمان محدود شود و توسط سایرین دیده نشود. پس دومین مجموعهای است از کاربران، گروهها و Projectها که در شکل زیر میتوانید آن را مشاهده نمایید:
Glance
Glance چیست؟ این سرویس که با نام OpenStack Image Service نیز نامیده میشود برای تهیه image از دیسکها و سرورها استفاده میشود. بهطور کلی اگر با مفاهیم Clone و Template در VMWare آشنایی دارید باید بدانید که Glance نیز چیزی به همان شکل را در OpenStack انجام میدهد.
Ceilometer
Ceilometer چیست؟ با استفاده از آن سرویسهای مرتبط با Billing به مشتریان Cloud ارائه میگردد. میزان استفاده کاربران از سرویسهای دریافتی کاملاً قابل سنجش توسط Ceilometer است.
Heat
Heat چیست؟ یکی از اجزای مهم محیط ابری، Orchestration است. Heat نرم افزاریست اختصاصی در این زمینه که این امکان را برای کاربران فراهم میکند که بهصورت اتوماتیک اقدام به ساخت اجزایی مانند Networks، instances، storage devices و غیره نمایند.
Provisioning and Deployment
یکی از قسمتهای کلیدی توسعه پذیری Cloud، به حداقل رساندن هزینههای عملیاتی آن است که برای دستیابی، باید به میزان زیادی انجام عملیات در آن را بهصورت اتوماتیک در آورد که در نتیجه آن، انجام کارهای دستی و همچنین شانس ایجاد خطا، به میزان زیادی کاهش مییابد. سیستمهایی مانند Puppet، Chef، Ansible، JuJu، Salt و CFEngine به عنوان Configuration Management System در راهاندازی این سیستم اتوماتیک به کمک ما میآیند.
در نمای کلی، نحوه عملکرد این سیستم اتوماتیک اینگونه است که شما با استفاده از PXE boot و TFTP server اقدام به نصب اتوماتیک سیستم عامل میکنید و سپس از طریق نرم افزارهایی که برای پیکربندی اتوماتیک در ردهت و اوبونتو وجود دارند مانند Kisckstart و Preseed اقدام به پیکربندی اتوماتیک سیستم عاملها مینمایید. همچنین به عنوان یک راهکار جایگزین میتوانید از رویکرد image-based نیز استفاده نمایید مانند systemimager که همانطور که از نام آن پیداست ماشینهای جدید را از روی image از قبل ساخته شده، میسازد.
با توجه به اینکه اپراتورها همیشه در مرکز داده، کنار سرورها نیستند پس باید تا حد ممکن دسترسی ریموت را برای آنها فراهم کرد. اپن استک کاملاً قابل پیکربندی از راه دور است. اما در رابطه با سرور فیزیکی و دسترسی به تمام جزئیات آن مانند power management نیاز به پروتکلی بنام IPMI است که برای استفاده از آن نیاز است سرور نیز از آن پشتیبانی نماید. با استفاده از آن حتی میتوان PDU که کابل پاور سرور به آن وصل است را نیز کنترل کرد.
Cloud Controller
سیستم مدیریتی مرکزی اپن استک است که دارای یک high level view نسبت به منابع cloud است و معمولاً مدیریت Authentication را برعهده گرفته و از طریق message queue پیغامهایی را به کل سیستمها ارسال میکند. این کنترولر میتواند بر روی یک سرور قرار گیرد اما در محیطهای production برای تامین HA میبایست بیشتر از یک سرور برای آن در نظر گرفت. تمام درخواستهای کاربران ابتدا وارد این کنترولر شده و سپس بر اساس نوع درخواست به سمت سایر نودها مانند compute، استوریج و یا شبکه ارسال میشوند. سرویسهایی که توسط cloud controller مدیریت میشوند عبارتند از:
- Databases
- Message queue Service
- Conductor Services
- Authentication and authorization for identity management
- Image management services
- Scheduling services
- User dashboard
- API Endpoint
از لحاظ مشخصات سخت افزاری سروری که به cloud controller اختصاص داده میشود، میتواند با مشخصات سرور compute یکسان باشد. برای مثال اگر شما یک رک کامل compute داشته باشید، حداقل برای سرور کنترولر به هشت core و ۸ گیگ حافظه نیاز دارید. همچنین این امکان وجود دارد که از ماشینهای مجازی برای تمام و یا قسمتی از سرویسهایی که کنترولر مدیریت میکند، استفاده کرد. بدین شکل که برای هر سرویس یک ماشین مجازی مجزا اختصاص داد. مزیت استفاده از این روش در این است که مدیر شبکه میتواند با توجه به باری که بر روی هر سرویس است، میزان منابع آنها را بهراحتی کم و زیاد کند. همچنین در محیطهای production بسیار بزرگ نیز حتی ممکن است از سرورهای اختصاصی برای هر سرویس استفاده شود. البته باید بدانید که بهتر است تنها از ماشینهای مجازی، برای سرویسهای کنترلی استفاده نمایید و برای سرویسهایی مانند nova-compute یا Swift-Proxy یا Swift-Object از مجازی سازی استفاده نشود.
حال در ادامه سرویسهای موجود در cloud controller بیشتر شرح داده خواهند شد:
Database
واحد Compute در اپن استک از دیتابیس برای ذخیره سازی stateful information استفاده میکند و دیتابیس محبوب آن نیز Mysql است. از دست رفتن دیتابیس منجر به خطا میشود. در نتیجه بهتر است اقدام به کلاستر کردن آن نمایید تا SPOF را در آن حذف نمایید.
Message Queue
بیشتر سرویسهای اپن استک از این سرویس برای برقراری ارتباط با یکدیگر استفاده میکنند. برای مثال compute برای برقراری ارتباط با سرویس block storage و یا سرویس شبکه از message queue استفاده میکند. همچنین میتوانید بهصورت اختیاری برای هر سرویس notification را نیز فعال نمایید. نرم افزارهای محبوب برای این سرویس عبارتند از RabbitMQ، Qpid و 0MQ. اگر به هر دلیل این سرویس دچار مشکل شود، کلاستر تا آخرین پیغامی که ارسال شده به حالت readonly میرود. پس راهاندازی یک کلاستر برای این سرویس ضروری است، اما باید بدانید که راهاندازی آن کاری بسیار دردآور است. نرم افزار RabbitMQ دارای کلاستر داخلی است اما گزارشهای زیادی از مشکلات آن مخصوصاً در شبکههای بزرگ وجود دارد. نرم افزار Qpid نیز انتخاب پیش فرض ردهت است، قابلیت کلاسترینگ ندارد و باید از سایر راهکارها برای آن استفاده کرد مانند Pacemaker یا Coresync.
Conductor Services
در نسخههای قدیمیتر اپن استک، تمام سرویسهای nova-compute نیاز به دسترسی مستقیم به دیتابیس موجود در cloud controller داشتند که این مساله هم مشکل امنیتی و هم performance بوجود میآورد. اما در نسخههای بعدی با استفاده از سرویس conductor این مشکلات حل شد. این سرویس در نقش یک پراکسی عمل کرده و مانع ارتباط مستقیم nova-compute با دیتابیس میشود. تمامی درخواستها ابتدا وارد conductor service شده و سپس این سرویس از طرف nova-compute با دیتابیس ارتباط برقرار میکند.
نکته: اگر شما بهجای استفاده از neutron از nova-network و multi-host networking در محیط cloud استفاده مینمایید، سرویس nova-compute همچنان نیاز به دسترسی مستقیم به دیتابیس دارد.
سرویس conductor قابلیت توسعه افقی دارد و برای تامین fault tolerance نیاز به ساخت instance های بیشتری از آن دارید.
Application Programming Interface (API)
تمامی دسترسیهای عمومی چه مستقیم باشند از طریق command-line و چه از طریق داشبورد مبتنی بر وب، از سرویس API استفاده میکنند. شما باید انتخاب نمایید که میخواهید از APIهای سازگار آمازون EC2 استفاده نمایید و یا OpenStack API. استفاده از هر دو مشکلاتی را در زمینه imageها و instanceها ایجاد مینماید. برای مثال EC2 API از ID که از هگزادسیمال تشکیل شده است برای مراجعه به instanceها استفاده میکند در حالی که OpenStack API از name و digit برای این کار استفاده میکند. و یا EC2 API از DNS alias برای ارتباط با ماشینهای مجازی استفاده میکند اما OpenStack API از IP استفاده مینماید.
برای سرویسهای دیتابیس و message queue داشتن بیشتر از یک سرور API چیز بسیار خوبیست. میتوان برای این کار از تکنیکهای موجود در load balancerهای سنتی برای سرویس nova-api استفاده کرد.
Extensions
هر API در هسته خود دارای قابلیتها و تواناییهایی است که آن را قابل استفاده مینماید. اما گاهی اوقات قابلیتهایی هستند که میتوانید آنها را از طریق extension به آن API اضافه نمایید بدون اینکه نیاز به تغییر ورژن API باشد. البته برای این کار باید API مربوطه extensible باشد یعنی قابلیت اضافه کردن extension را داشته باشد.
Scheduling
سرویسی است که مسئول تعیین نود compute و storage برای ماشینهای مجازی و block storage volume است. این سرویس درخواست ساخت این منابع را از message queue دریافت کرده و سپس پروسه تعیین نود مناسب برای این منابع را آغاز میکند که پیش از این توسط فیلترهایی که به کاربر ارائه شده است، تعیین شده. یکی از اجزای آن Nova-Scheduler است که مخصوص ماشینهای مجازی و دیگری Cinder-Scheduler است که برای block storage volume است. هر دوی آنها قابلیت توسعه افقی را دارند و با توجه به اینکه همهی آنها به یک shared message queue گوش میدهند نیازی به استفاده از load balancer برای آنها نیست.
Images
این سرویس که پیش از این با نام glance مورد بررسی قرار گرفته است دارای دو قسمت Glance-API و Glance-registry است. قسمت اول مسئول تحویل images ها است و compute node از آن برای دانلود image ها از back end استفاده میکند. قسمت دوم اطلاعات متادیتای imageهای ماشینهای مجازی را نگهداری میکند و برای این کار نیاز به دیتابیس دارد.
S3 یکی از قابلیتهایی است که Glance-api از آن پشتیبانی میکند و شما را قادر میسازد که imageها را از Amazon S3 به سیستم خود fetch کنید.
Dashboard
یک اینترفیس مدیریتی مبتنی بر وب را که با استفاده از پایتون نوشته شده است و عموماً بر روی آپاچی اجرا میشود، ارائه مینماید و نام آن Horizon است. این داشبورد شامل قسمتی برای کاربران است که از طریق آن بستر مجازی خود را مدیریت میکنند و یک قسمت Admin area هم دارد که مخصوص اپراتورهای cloud است و از طریق آن میتوان کل محیط اپن استک را مدیریت کرد.
Authentication and Authorization
همانطور که از نام آن مشخص است وظیفه این سرویس احراز هویت و تعیین مجوزهای دسترسی است. این سرویس از پلاگینهای مختلفی برای تعیین نحوه احراز هویت پشتیبانی میکند که رایجترین آنها عبارتند از SQL database و LDAP. شما میتوانید این سرویس را هم با OpenLDAP لینوکس و هم با اکتیو دایرکتوری ویندوز ادغام نمایید.
Network Considerations
بهدلیل اینکه cloud controller از سرویسهای مختلفی میزبانی میکند، باید قادر باشد ترافیک زیادی را جابهجا نماید. برای مثال اگر شما انتخاب نمایید که اپن استک از Image Service در cloud controller میزبانی نماید، پس باید cloud controller قادر باشد imageها را با سرعت قابل قبولی انتقال دهد.
به عنوان مثالی دیگر اگر شما انتخاب نمایید که از Single-host Networking استفاده نمایید یعنی Cloud Controller به عنوان گیتوی همه instanceها باشد، پس میبایست Cloud Controller توان انتقال تمام ترافیکی که بین cloud و اینترنت جابهجا میشود را داشته باشد.
پیشنهاد میشود که در این حالت از یک کارت شبکه 10G استفاده نمایید. همچنین میتوان از دو کارت شبکه 10G استفاده کرده و آنها را full bonded کرده تا پهنای باند به 20G برسد. البته این در حالی است که شما نمیتوانید در انتقال برای مثال یک image از کل 20G استفاده نمایید بلکه در این حالت اگر بخواهید ۲ عدد Image را منتقل کنید، هر کدام از آنها از یکی از کارت شبکهها استفاده میکند.
Compute Nodes
بعد از بررسی Cloud Controller، نوبت به سرورهای Compute و منابع و سرویسهای مرتبط با آن میرسیم که در ادامه همراه با جزئیات، مورد بررسی بیشتر قرار خواهند گرفت.
یکی از پارامترهای مهم در سرورهای Cloud انتخاب CPU است. باید ابتدا بررسی نمایید که آن پردازشگر از مجازی سازی پشتیبانی کند که حرف x در نام پردازشگرهای اینتل و حرف v در AMD، نشانگر پشتیبانی از مجازیسازی است. تعداد هستههای پردازشگر و همچنین پشتیبانی از hyperthreading در پردازشگرهای اینتل نیز از اهمیت زیادی برخوردار است.
Hyper Threading در واقع اصطلاحی است که اینتل استفاده میکند و همان تکنولوژیای است که AMD آن را Simultaneous Multithreading یا SMT مینامد. در این تکنولوژی، CPU هسته فیزیکی خود را به دو هسته مجازی که Thread نامیده میشود، تقسیم میکند. HT هر هسته را برای انجام دو کار استفاده میکند در نتیجه کارایی CPU افزایش مییابد. البته سیستم عامل، BIOS و نرمافزارهایی که استفاده میکنید نیز باید از این قابلیت پشتیبانی نمایند. البته دیده شده که غیرفعال کردن این قابلیت در محیطهایی که از Compute استفاده بسیار زیادی میشود، مفیدتر است. پس حتماً پیشنهاد میشود که برای تست کارایی در هر دو حالت خاموش و روشن، این قابلیت آزمایش شود.
بعد از انتخاب پردازشگر، نوبت به هایپروایزر میرسد. اپن استک از هایپروایزرهای زیر پشتیبانی میکند:
- KVM
- LXC
- QEMU
- ESXi
- Xen
- HyperV
- Docker
شما میبایست با توجه به پارامترهایی مانند تجربه، ویژگیها و کامیونیتیهای هر کدام، اقدام به انتخاب هایپروایزر مناسب خود نمایید. در صدر لیست هایپروایزرهایی که در اپن استک استفاده میشود، KVM قرار دارد. همچنین این امکان وجود دارد که بر روی هاستهای مختلف با استفاده از host aggregate و یا Cells، هایپروایزرهای گوناگونی نصب نمایید ولی بر روی یک هاست تنها میتوان یک هایپروایزر نصب کرد.
در مرحله سوم باید راهکار Instance Storage خود را انتخاب نمایید. برای این کار سه راهکار وجود دارد. در راهکار اول شما برای هر سرور به میزان کافی دیسک تهیه کرده و با استفاده از Distributed File System کاری میکنید که تمامی دیسکهای سرورها در یک نقطه mount شده تا برای همه قابل استفاده باشند. در راهکار دوم برای سرورها دیسک تهیه میکنید ولی دیگر آنها را اختصاصی برای همان سرور در نظر میگیرید و از DFS استفاده نمیکنید. در راهکار سوم استوریج در جایی خارج از سرورهای Compute خواهد بود و از طریق شبکه، سرورها دیتای خود را بر روی آن کپی میکنند. هر کدام از این راهکارها دارای مزایا و معایبی است که میبایست با توجه به شرایط و بودجه خود، اقدام به انتخاب آنها نمایید.
قابلیتی به نام Migration در اپن استک وجود دارد که از طریق آن میتوان یک instance را بدون هیچگونه وقفه در عملیات، از یک سرور به سرور دیگر منتقل کرد. این قابلیت در vMware با نام vMotion شناخته میشود. البته این قابلیت فقط با استفاده از Shared Storage بهدرستی کار میکند. برای زمانهایی که از Nonshared Storage استفاده میکنید، قابلیتی به نام KVM live block migration به کمک شما میآید. نرم افزارهای QEMU و Libvirt که سازگار با اپن استک هستند در نسخههای جدیدتر خود، توانستهاند انجام این عملیات را بهبود ببخشند.
اگر میخواهید از Shared Storage Live Migration پشتیبانی نمایید باید یک DFS پیکربندی نمایید. گزینههایی که دارید عبارتند از NFS، GlusterFS، MooseFS و Lustre که تمامی آنها برای این کار جواب دادهاند و بهتر است فایل سیستمی را که بیشتر از همه با آن کار کردهاید انتخاب نمایید. در صورتی که با هیچکدام تاکنون کار نکردهاید بهتر است از NFS استفاده نمایید.
نحوه اختصاص منابع سرور
اپن استک این اجازه را به شما میدهد که بیشتر از میزان ظرفیت CPU و RAM سرور به ماشینهای مجازی خود اختصاص دهید. در نتیجه میتوانید تعداد بیشتری instance در cloud بسازید که البته باید بدانید که ممکن است به میزانی از کارایی آنها پایینتر بیاید. بهصورت پیش فرض اپن استک از نرخهای ۱۶:۱ برای CPU و ۱.۵:۱ برای RAM استفاده مینماید. نرخ ۱۶:۱ بدین معنی است که سرویس Scheduler بهازای هر Physical Core میتواند حداکثر تا ۱۶ عدد Virtual Core اختصاص دهد. برای مثال اگر سرور شما دوازده Core دارد، Scheduler قادر به دیدن ۱۹۲ عدد virtual core است. حال اگر بهطور میانگین به هر instance چهار عدد Core اختصاص دهید، میتوانید ۴۸ ماشین مجازی بر روی سرور داشته باشید. بهطور یکسان Scheduler میتواند ۱.۵ برابر میزان Ram به ماشینها اختصاص دهد. برای مثال اگر سرور ۴۸ گیگابایت داشته باشد، میتواند حداکثر تا ۷۲ گیگابایت اختصاص دهد. در نتیجه شما میبایست با توجه به نوع استفاده خود نرخ مناسبی از اختصاص پردازشگر و حافظه را انتخاب نمایید. بهترین راهحل در این موارد مانیتور کردن سرور است تا هیچوقت منابع سرور در اصطلاح Overcommitment نشوند یعنی میزان استفاده از میزان ظرفیت واقعی آنها بالاتر نرود.
Segregating Your Cloud
وقتی سایز کلاستر شما در Cloud دائماً در حال رشد است، شما به راههایی که از طریق آنها به دلایل مختلف اقدام به جداسازی یا همان segregate کردن کلاستر خود نمایید، فکر خواهید کرد. شاید شما بخواهید چندین کپی از دیتای خود را در regionهای مختلف داشته باشید و یا به Business Continuity در زمانهایی که یک دیتاسنتر دچار مشکل میشود، اهمیت بیشتری بدهید. به عبارت بهتر ممکن است شما بخواهید قسمتهای مختلف کلاستر خود را بر اساس قابلیتها، تقسیم نمایید تا از این طریق بتوانید مشتریان خود را در صورتی که نیازهای خاصی دارند، برای مثال نیاز به دیسکهای با سرعت بالا دارند و یا سخت افزار خاصی را طلب میکنند، به قسمت از پیش ساخته شده مورد نظر هدایت نمایید. اپن استک دارای چهار روش برای اینکار است:
- Cells
- Regions
- Availability Zones
- Host Aggregates
این چهار روش را میتوان در دو گروه کلی قرار داد:
۱ – روشهای Cells و Regions برای جداسازی کل Cloud و اجرای چندین Compute Deployment بهصورت مجزا استفاده میشود.
۲ – روشهای Availability zones و host aggregates برای تقسیم بندی یک Compute Deployment استفاده میشوند.
نکته: یک Compute deployment میتواند شامل یک cloud controller و چندین هاست باشد. وقتی میگوییم چند compute deployment، یعنی هر کدام برای خود cloud controller و هاستهای مختص به خود دارند.
۱ – Cells
در این روش که فاقد استفاده از تکنولوژیهای پیچیده است، هاستها در گروههایی به نام cell تقسیمبندی میشوند. سِلها نیز در یک ساختار درختی قرار میگیرند. بالاترین سل میشود API Cell که سرویس nova-api بر روی آن قرار میگیرد و سرویس nova-compute بر روی آن نصب نخواهد شد. سایر سلهای درخت که سلهای child نامیده میشوند، تمام انواع سرویسهایی *-nova را میزبانی خواهند کرد به غیر از nova-api. هر سل سرویسهای message queue و دیتابیس خود را خواهد داشت و همچنین سرویس nova-cells نیز که ارتباط بین API Cell را با Child Cells مدیریت میکند، بر روی تمام سلها نصب میگردد.
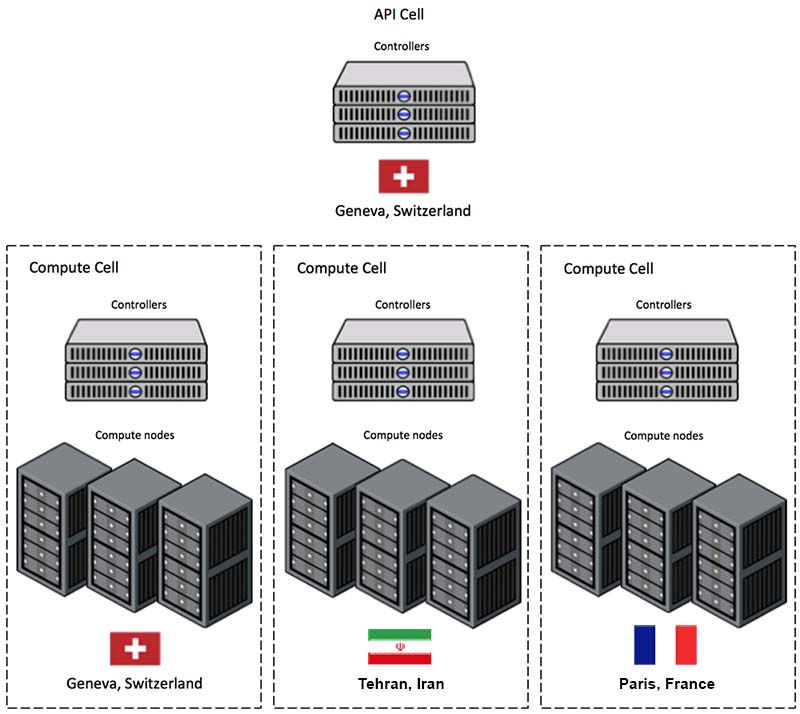
۲ – Regions
این روش نیز به مانند Cells است با این تفاوت که بهجای استفاده از یک API Endpoint برای همه نواحی، برای هر ناحیه یک API Endpoint جداگانه قرار میدهیم. کاربران وقتی میخواهند اقدام به ساخت یک instance کنند باید صراحتاً region خود را انتخاب کنند، با این حال پیچیدگیهای اضافه اجرای یک سرویس جدید در اینجا کمتر میشود.
با استفاده از پارامتر AVAILABLE_REGIONS میتوان داشبورد horizon را برای استفاده از قابلیت چند region پیکربندی کرد.
روش سوم و چهارم مفاهیم بسیار گیج کنندهای در اپن استک میباشند که در جاهای مختلف تعاریف مختلفی نیز از آنها مشاهده مینمایید. با اینکه این دو بسیار شبیه هم هستند اما یکسان نیستند. در شکل زیر تفاوت در نوع استفاده این دو را مشاهده مینمایید:
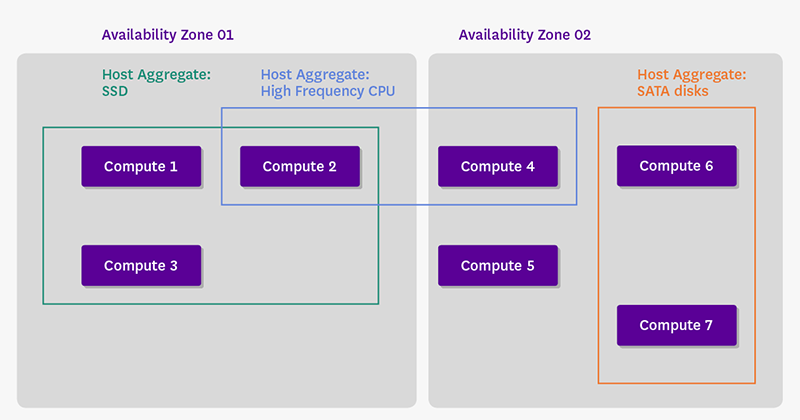
۳ – Availability Zones
از این مکانیزم که به مخفف AZ نیز میشناسند، معمولاً برای گروهبندی هاستها بر اساس مناطق جغرافیایی استفاده میشود و قابل دیده شدن توسط مشتریان است و آنها میتوانند از طریق آن اقدام به انتخاب region خود نمایند. هر هاست فقط میتواند در یک availability zone قرار بگیرد.
۴ – Host Aggregates
مکانیزمی است برای پارتیشنبندی یا به عبارتی گروهبندی کردن هاستهای کل اپن استک و یا یک region از اپن استک بر مبنای یک مشخصه دلخواه. برای مثال ساخت یک aggregate با هاستهایی که دیسکهای SSD دارند. سپس ادمینها اقدام به ساخت flavorهای عمومی مینمایند و سپس مشتریان قادرند از طریق flavor که در واقع نوع سخت افزار مورد نیاز را تعیین میکند، اقدام به ساخت instanceهای خود در aggregate مربوطه کنند. پس همانطور که مشاهده میکنید aggregateها برای مشتریان به نمایش در نمیآیند و آنها فقط میتوانند بهصورت غیرمستقیم و از طریق flavorها از گروههای ساخته شده استفاده نمایند.
ادمین شبکه میتواند بهصورت اختیاری معماری خود را بگونهای طراحی کند که host aggregateها را بهصورت availability zone نمایش دهند. در ضمن برخلاف AZ در اینجا هر هاست میتواند در چند Aggregate قرار بگیرد.
Storage Decisions
استوریج یکی از مباحث بسیار مهم در اپن استک است که در جاهای مختلف به آن اشاره میشود. انواع مختلف استوریج که در بازار وجود دارد، انتخاب را برای مهندسین cloud بسیار مشکل کرده است. در این قسمت در رابطه با پیکربندی استوریج و انواع آنها توضیح داده خواهد شد. در ابتدا دو نوع مختلف استوریج ephemeral و persistent و تفاوتهای آنها را بررسی میکنیم.
دیسک ephemeral همانطور که از نامش بر میآید موقتی است و میزانی از فضا را از روی لینوکس هایپروایزر و یا از روی دیسکهای خارجی که از طریق NFS در سیستم عامل mount شدهاند، به instance مربوطه اختصاص میدهد. در این حالت با terminate شدن ماشین مجازی آنها نیز ناپدید میشوند. به همین دلیل از آنها برای ذخیره سازی دیتاهای مهم استفاده نمیشود و تنها برای کارهای موقتی از آنها استفاده میشود.
دیسکهای persistent دقیقاً در نقطه مقابل ephemeral قرار دارند. برای ذخیره سازی دائمی دیتا استفاده میشوند و خاموش شدن instance هیچ تاثیری بر روی دیتای آن ندارد. این نوع از استوریج به سه قسمت زیر تقسیم میشود که در روبروی آنها، نام سرویس کنترل کننده هر کدام در اپن استک ذکر شده است:
Object Storage –> Swift
Block Storage –> Cinder
File Share Storage –> Manila
در Object storage کاربران با استفاده از یک REST API میتوانند از هر جایی به آن دسترسی داشته باشند در حالی که Block Storage ابتدا به ماشین مجازی attach شده و سپس آن را درون سیستم عامل mount کرده و فرمت میکنیم تا امکان دسترسی تنها در آن VM فراهم گردد. از Object Storage بهدلیل توانایی نگهداری دریایی از متادیتا در خود، برای ذخیره سازی Unstructured data استفاده میشود که در نتیجه آن، سرعت جستجوی فایلها بسیار بالا میرود و در این استوریج بهجای استفاده از RAID از روش Erasure coding استفاده میشود که HA را برای دیتا فراهم مینماید. اما در Block Storage فقط متادیتای محدودی در حد نام فایل، پسوند فایل و تاریخ ساخته شدن آن، ذخیره میشود و عموماً از این نوع استوریج برای نرم افزارها و دیتابیسهایی که نیاز به low-latency دارند استفاده میشود.
در ادامه نرم افزارهای مختلفی که در زمینه معماری استوریج بسیار کارایی دارند را معرفی مینماییم:
Ceph
Ceph چیست؟ یک پلتفرم ذخیره سازی متن باز Software-Define Storage است که امروزه در سیستمهای cloud بسیار مورد استفاده قرار میگیرد و رقیبی جدی برای محصول vSAN شرکت VMWare است. ساختار اصلی این پروژه بهصورت Object میباشد اما با استفاده از API میتواند هر سه حالت File، Object و Block را برای دیتا فراهم نماید.
Gluster
Gluster چیست؟ این پلتفرم نیز به مانند Ceph است با این تفاوت که مبنای ساختاری آن بهصورت سنتی و بر روی Block است اما باز میتواند هر سه حالت Object، file و Block را پشتیبانی نماید.
LVM
LVM را به عنوان Dynamic Partition هم میشناسند، Logical Volume Manager به شما این امکان را میدهد که در سیستم عامل لینوکس، یک فایل سیستم را بهصورت همزمان بر روی چندین پارتیشن قرار بدهید. اگر شما بر روی یک پارتیشن فضای کمی دارید و دچار کمبود فضا شدهاید و میخواهید فضای بیشتری به پارتیشن مورد نظر بدهید، شما میتوانید از LVM استفاده کنید. از LVM میتوان به عنوان یک لایه نرم افزاری در بالای چندین هارد دیسک و پارتیشن یاد کرد که این قابلیت را به ما میدهد که بدون اینکه کاربر متوجه شود پارتیشنها را تغییر اندازه بدهیم، پارتیشن بندی را مجدداً انجام دهیم، هارد دیسکها را تعویض کنیم و همچنین بکاپ گیریها را به سادگی انجام دهیم.
ZFS
یکی از فایل سیستمهایی است که در چند سال اخیر سروصدای بسیار زیادی کرده است. این فایل سیستم بسیار پیشرفته و شاید فراتر از زمان خود طراحی شده است و دارای قابلیتهای فراوانی است. این فایل سیستم قابلیت Volume Manager را نیز دارد. شرکت Sun Solaris که مالک این فایل سیستم میباشد، درایور مخصوص اپن استک آن را نیز ارائه داده است.
Sheepdog
این محصول نیز به مانند Ceph یک پلتفرم ذخیره سازی distributed میباشد.
Network Design
طراحی معماری شبکه در پلتفرمهای Cloud بسیار پیچیدهتر از شبکههای سنتی است و به همین دلیل نیاز به دانش و تجربه زیاد دارد. در ادامه در رابطه با مفاهیم مختلف آن بحث خواهیم کرد.
طراحی یک Management Network به صورتی که حتی از کارت شبکهها و سوئیچهای جدا استفاده شود، از الزامات یک شبکه cloud است. این جداسازی باعث میشود هیچگاه ترافیکی که توسط guest ها ایجاد شده است، وقفهای در روند کار ادمین و اپراتور cloud نگذارد. همچنین باید ساخت شبکههای خصوصی دیگر برای ارتباطات اجزای داخلی اپن استک مانند message queue و compute را نیز در نظر بگیرید، که معمولاً آنها را از طریق VLAN جدا مینماییم.
در معماری شبکه شما دو گزینه دارید، یا از nova-network استفاده نمایید و یا از neutron. هر کدام از این روشها مزایا و معایب خود را دارند که میبایست با توجه به نوع معماری و نیازمندیهایی که دارید یکی از این روشها را انتخاب نمایید. پروژه neutron با این ایده طراحی شده است که هر قابلیتی که میتوانید با استفاده از سخت افزار واقعی ایجاد نمایید، میتوانید دقیقاً برابرش را با استفاده از این نرم افزار داشته باشید. مثلاً هر tenant میتواند عناصر شبکهای مختص به خود مانند روتر و dhcp را داشته باشد.
در ادامه چند مورد از قابلیتها را مورد بررسی بیشتر قرار میدهیم:
VLAN Configuration within VMs
با استفاده از ساخت VLAN میتوان به راحتی تمامی Projectها را از هم جدا کرده و از این طریق امنیت آنها را بالا ببریم. همچنین میبایست پورت سرور Compute در سمت سوئیچ را در این حالت در وضعیت ترانک قرار داده و تمامی VLAN ها را در سوئیچهای شبکه تعریف نماییم.
Multi-NIC Provisioning
یعنی میتوان بهراحتی به هر instance چند کارت شبکه اختصاص داد که در موارد مختلف کاربرد دارد.
Multi-Host and Single-Host Networking
سرویس nova-network قابلیت اجرای هر دو را دارد. در حالت Multi-host هر سرور compute یک نسخه از nova-compute را در خود اجرا میکند و در نتیجه هر instance از سرور خودش به عنوان راه خروج اینترنت استفاده مینماید. همچنین در این حالت تمام security group ها در خود سرورها میزبانی میشوند. در روش Multi-host میبایست برای هر سرور یک public IP نیز اختصاص داد که بتوانند با اینترنت در ارتباط باشند. در روش Single-host یک سرور مرکزی مانند cloud controller سرویس nova-network را اجرا مینماید و تمامی سرورهای دیگر ترافیک instance های خود را به سمت آن سرور مرکزی ارسال میکنند و آن نیز ترافیک را به سمت اینترنت میفرستد. همچنین security group ها نیز تنها در همان سرور cloud controller، برای تمامی instance ها، میزبانی میشود.